DeepFellow Infra Web Panel
DeepFellow Infra lets you manage your models. To install Infra, follow the Installation Guide.
Accessing Infra Web Panel
Type the following in your terminal:
deepfellow infra infoYou will get output similar to this:
$ deepfellow infra info
💡 Information about DeepFellow Infra:
NAME: infra
INFRA_URL: https://df-infra-node-1.com
INFRA_MESH_URL: wss://df-infra-node-1.com
INFRA_PORT: 8086
INFRA_IMAGE: hub.simplito.com/deepfellow/deepfellow-infra:latest
MESH_KEY: *****
INFRA_API_KEY: *****
INFRA_ADMIN_API_KEY: *****
CONNECT_TO_MESH_URL: undefined
CONNECT_TO_MESH_KEY: undefined
INFRA_DOCKER_SUBNET: deepfellow-infra-net
INFRA_COMPOSE_PREFIX: dfd834zh_
INFRA_DOCKER_CONFIG: /home/mark/.deepfellow/infra/docker-config.json
INFRA_STORAGE_DIR: /home/mark/.deepfellow/infra/storage
METRICS_USERNAME: SDjtoe8Z
METRICS_PASSWORD: *****Sensitive values are masked by default. Add the --secret flag to reveal them:
deepfellow infra info --secretHead to the UI at http://localhost:8086.
In the pop-up window enter the value of INFRA_ADMIN_API_KEY. The services window will appear:

Services
Models are organized under "services". Each service is named after the backend, e.g. "ollama", or after the provider, e.g. "openai". Services group models from the same family.
Choosing Services
Available LLM services – ollama, llamacpp, and vllm differ in their level of hardware integration, including dependencies on specific CPU instruction sets.
To minimize hardware compatibility issues, consider the following services:
- ollama – Recommended for most users. Automatically adapts to your hardware configuration with minimal setup required.
- llamacpp – Supports models outside the ollama repository and the GGUF model format. May require extra configuration due to a higher chance of hardware compatibility issues.
- vllm – Offers the highest performance but carries the highest risk of hardware-related complications. Recommended for experienced users who are confident in troubleshooting and system configuration.
Recommendation: If you're not sure which service to choose, start with ollama.
Installing Services
To install a particular service, click install. You will be prompted with the window where you can choose service parameters.
Get the required API key before installing each service to use models with our anonymization layer:
- "openai" service - OpenAI API Key
- "google" service - Gemini API Key
- "claude" service - Anthropic API Key
- "ollama-cloud" service - Ollama Cloud API Key
Hardware selection depends on availability:

vLLM CPU mode is available only with processors supporting AVX-512 – learn more in vLLM docs. We recommend using 'ollama' or 'llamacpp' services instead, whenever possible. They provide the smoothest experience for now.
After the chosen service is installed, it will appear in the grid.
Uninstalling Services
Simply click "Uninstall" button to uninstall a service. You will have two options to choose:
- Uninstall - uninstalls the service but keeps its associated files, including model files
- Purge - uninstalls the service with its associated files, including model files
Models
Installing Models
Click on "Models" button on the desired service. You will see a list of available models:

You can filter model list by name, type. You can also show models which are:
- installed / not installed
- custom / not custom
Click on "Install" button to install selected model.

You can set the model alias. You can also decide how much time it can stay inactive before removing it from the graphic card memory. You can also adjust its context length.
After a model is installed, its card shows an estimated memory footprint (RAM (est.) on CPU, VRAM (est.) on GPU). Use it to judge how many models will run on the same machine at once and to avoid out-of-memory failures.
Uninstalling Models
Simply click "Uninstall" button to uninstall a model.
A window will open asking if you want to uninstall the model with its files.
After clicking uninstall, the model will stay downloaded but not installed.
Then, you can click install or purge button.
Clicking purge removes the model completely. It will have to be downloaded again in order to install.
Testing Models
At any time after installing a given model you can test whether it is healthy. To do this click "Test" button on the model card, and you will get the result:

Custom Models
You can install your own custom models. Installed model must adhere to at least one of the criteria below:
- Is present in Ollama library -- use ollama service,
- Any model available in HuggingFace in GGUF format -- use llamacpp service,
- Any model available in HuggingFace supported by vLLM -- use vllm service,
- Any model from OpenAI/Google -- use openai/google service,
- Any image generation model compatible with stable diffusion (e.g. Civitai, HuggingFace) -- use stable-diffusion service,
- Any LoRA compatible with stable diffusion (e.g. Civitai, HuggingFace) -- use stable-diffusion service,
- Any docker image -- use custom service.
- Any reranking model -- use rerank service.
- Models hosted on a separate Ollama instance -- use ollama-external service.
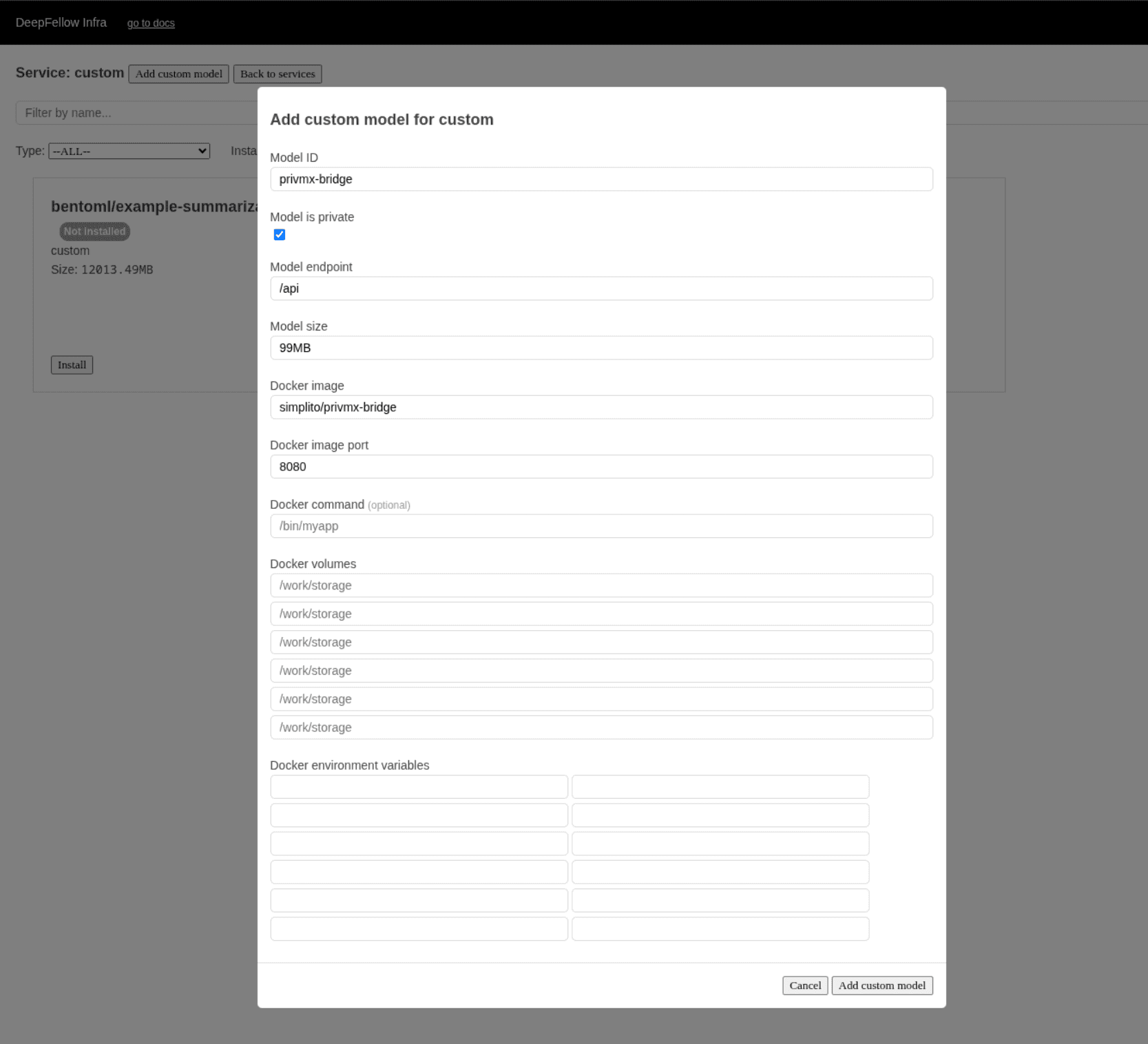
Read Using Custom Models guide to check the details.
Install
The install procedure is similar for all the services. Exception is 'custom' service - read Using Custom Models guide to check the details.
As an example, if you want to add custom model (qwen3-embedding:0.6b -- go to Ollama library) to your 'ollama' service:
- Go to the services view,
- Locate 'ollama' tab and clik 'Install' if not already installed,
- Click "Add custom model" button,
- In the pop-up window enter Model ID
qwen3-embedding:0.6b, - Enter Size
639MB, - Chose
embeddingModel type from the drop-down. New model tab will be shown, - Click "Install" button,
- In the pop-up window add optional parameters and click "Install" to confirm,
- After a while your model will appear in the models list with green label "Installed". Now you can use your model as normal.
Custom models are used exactly the same way as non-custom ones. You use their intentifiers the same way in your inference requests or code.
Uninstall
Removing custom model requires two actions:
- uninstalling model,
- removing custom model tab.
Uninstalling model
- Go to the services view,
- Click "Models" on the tab of the service (e.g. 'ollama') model was installed from,
- Search the model you want to uninstall (e.g.
qwen3-embedding:0.6), - Click "Uninstall" to remove the model.
Removing custom model tab
- Inside the model view search for the custom model name (e.g.
qwen3-embedding:0.6), - Click "Remove custom model".
MCP Servers
DeepFellow can register MCP servers in three ways: running a stdio-based server in Docker via a built-in bridge, proxying a remote MCP endpoint, or using a custom Docker image. All three are configured through a single modal on the mcp service's Models page.
Read the MCP Servers guide for full details.
API Documentation
To access the DeepFellow Infra API documentation, click the "Go to Docs" button in the upper left corner.
Next steps
You can head to the tutorials related to using specific services listed here:
- speaches-ai:
- text-to-speech - turn text into audio
- speech-to-text - transcribe speech into text
- translation - translate speech to text in English
- Use OpenAI via DeepFellow - get OpenAI API Key to use OpenAI models with our anonymization layer
- Use Google AI via DeepFellow - get Gemini API Key to use Google models with our anonymization layer
- Use Anthropic via DeepFellow - get Anthropic API Key to use Claude models with our anonymization layer
We use cookies on our website. We use them to ensure proper functioning of the site and, if you agree, for purposes such as analytics, marketing, and targeting ads.